Fundamentals of Reinforcement Learning Week4 Notes
Policy Evaluation and Control
- Policy evaluation is a task of determining the state-value function
, for a particular policy . It is also called prediction problem. - Control is the task of improving an existing policy. it is also called policy improvement.
- Dynamic programming can be used to solve both problems, if we can get the dynamic function
, which appears in all bellman functions about and .
Policy Evaluation
Recall the formula of
According to the above formula, it is a system of
It is proved that the state-value function will be optimized.
Moreover, there are two methods about implementing the iterate formula. One is to use two array to represent the state before and after one iteration. Another is to only use the original state array and update in-place. In practice, the second one provides us a faster converge speed, since it gets to use the updated values sooner, and occupies less memory space than the two array version implementation.
Then the algorithm pseudo-code is:

In practice, we almost cannot reach the convergence in short time, so that we set a margin
Policy Control
Recall that,
If the greedification, the
Here,
Generalized Policy Iteration
The generalized policy iteration (GPI) refers to all the ways we can interleave policy evaluation and policy improvement. It can be showed as below,
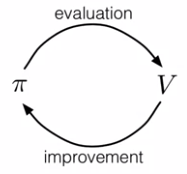
Policy Iteration
Policy iteration is the process of finding an optimal policy by iteratively using policy evaluation and policy improvement (control). Such as,
where
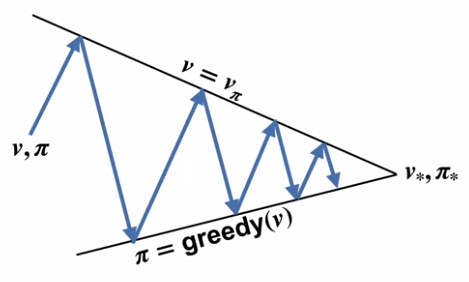
The algorithm pseudo-code is:

Notes:
- Pros: Policy iteration often converges in surprisingly few iterations.
- Cons: each of the iteration involves policy evaluation, which may sweeps through the state set multiple times and consume lots of time before convergence.
Value Iteration
Value iteration sweeps once in policy evaluation part and then do policy improvement. By combining the two formulas, the update formula would be,
It can be showed as,
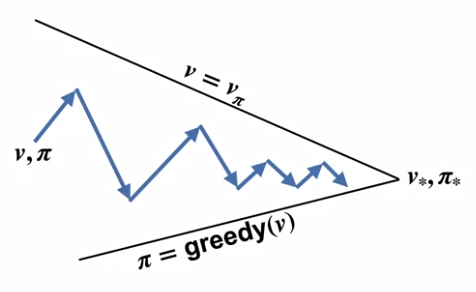
For each iteration step, it doesn’t finish it completely but continuously improve itself until convergence. The algorithm pseudo-code is,

Asynchronous Dynamic Programming
The two iteration methods above are all synchronous DP, which means they systematically sweep the state set in one iteration. However, if the state set is very large, such as
Asynchronous DP, instead, update values of states in any order. Some states may get several updates while other states are not visited. In order to guarantee convergence, asynchronous DP must continue to update the value of all states.
Efficiency of Dynamic Programming
Monte Carlo method
The key of Monte Carlo method is to calculate the mean of several samples under current state. The formula is,
For each state, the method will average samples to get the value of the current state. When the number of state is large, it is time consuming.
Brute-Force Search
Brute-Force Search is the most basic idea on finding the optimal policy. However, due to the number of possible state combination growth exponentially when states increase,
Dynamic Programming
Compare to Monte Carlo method, DP method use successors calculated state to calculate current state value, which do not handle each states independently. The method is also called bootstrapping.
Also, Policy iteration can control the running time to polynomial time in